In this blog, I will share my experience of working with Apache Kafka. I will talk about the different use-cases, basic architecture followed by a quick example.
In one the companies that I worked for, I was asked to replace the existing message queueing framework. The existing solution we were using was not scaling. Apache Kafka was one of the frameworks we were evaluating and ultimately we ended up moving to Kafka after running certain performance tests.
So what are the use cases that Kafka can help with?
Message queue: One of the important use cases for Kafka is a message queue system. In a message queue system, multiple producers can send messages to the same queue. Consumers process a message, it’s locked or removed from the queue.
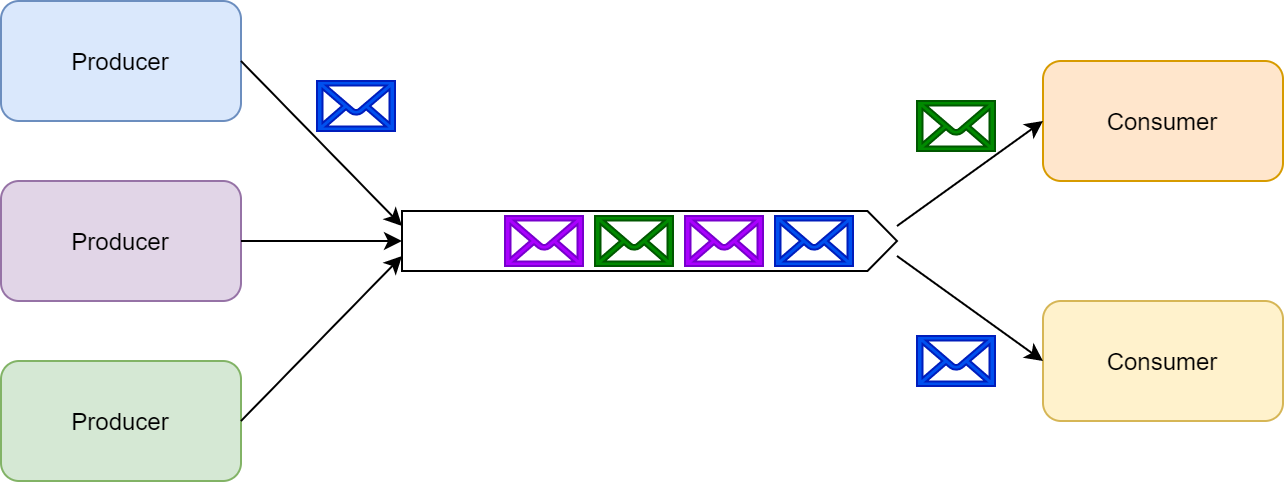
Publish Subscribe: In the publish/subscribe (or pub/sub) system, a single message can be received and processed by multiple subscribers concurrently.
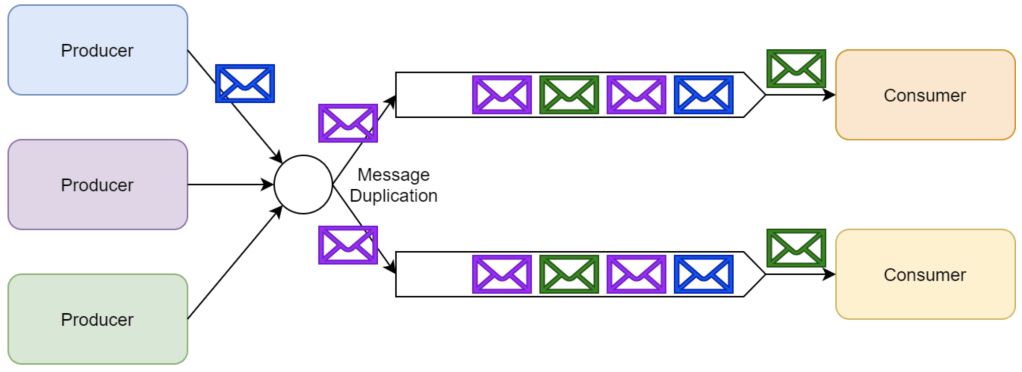
Kafka as a Storage system: Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows producers to wait on acknowledgement so that a write isn’t considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
The disk structures Kafka uses scale well—Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server. As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation. For details about the Kafka’s commit log storage and replication design, please read this page. Kafka uses sequential disk I/O to boost performance.
From Kafka documentation: “The linear reads and writes are the most predictable of all usage patterns, and are heavily optimized by the operating system. A modern operating system provides read-ahead and write-behind techniques that prefetch data in large block multiples and group smaller logical writes into large physical writes. A further discussion of this issue can be found in this ACM Queue article; they actually find that sequential disk access can in some cases be faster than random memory access!“
Stream processing: For this use case there are continual streams of input data which needs to be processed and then emit them out as an output stream. For these type of complex transformations Kafka provides a fully integrated Streams API. This allows building applications that do non-trivial processing that compute aggregations off of streams or join streams together. I will be covering this topic in a separate blog in a few weeks from now.
Basic Architecture
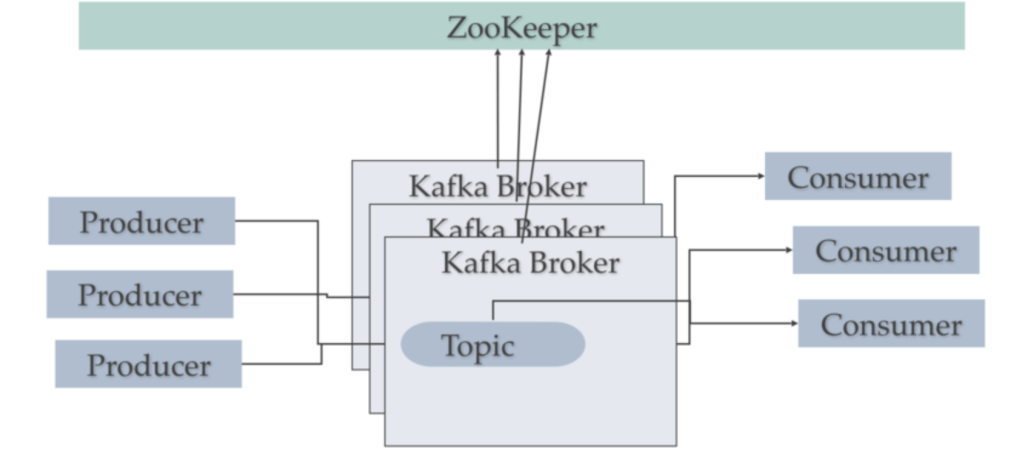
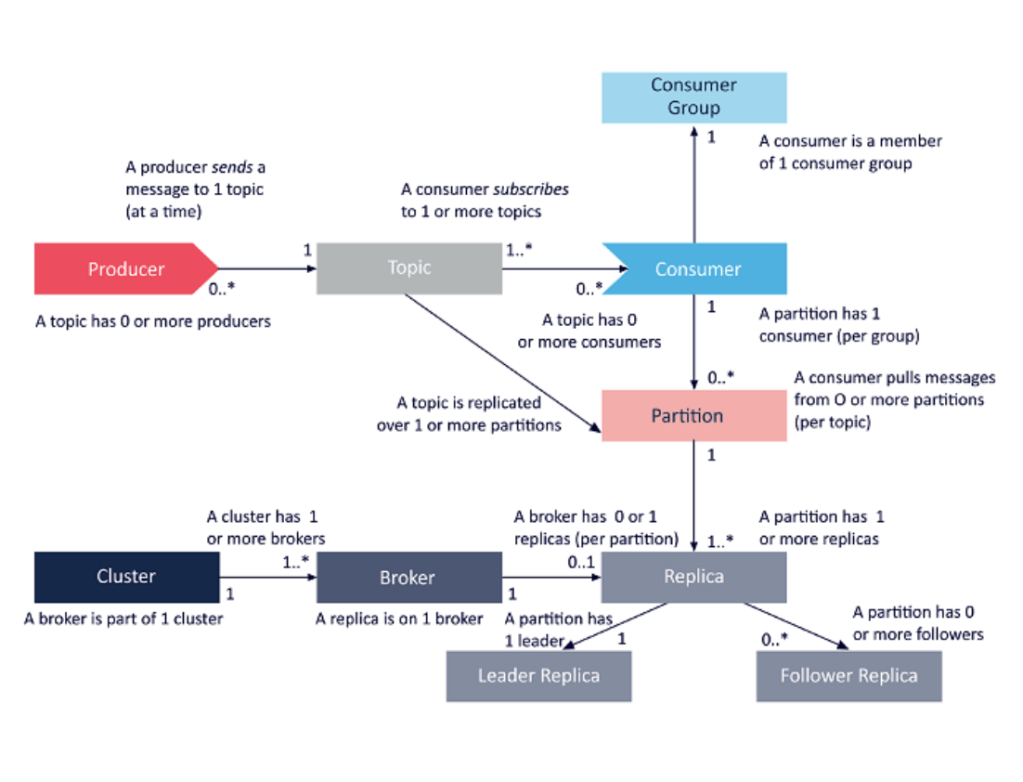
A Kafka cluster has 4 main components:
Producer: These machines/nodes are the ones talking to the Kafka cluster and publish records for a particular topic. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record).
Broker: A Kafka cluster is made up of multiple Kafka Brokers. Kafka Brokers contain topic log partitions. Connecting to one broker bootstraps a client to the entire Kafka cluster. For failover, you want to start with at least three to five brokers. A Kafka cluster can have hundreds of Broker in a system.
Zookeeper: Kafka uses Zookeeper to do leadership election of Kafka Broker and Topic Partition pairs. It also manages service discovery for Kafka Brokers that form the cluster. Zookeeper sends changes of the topology to Kafka, so each node in the cluster knows when a new broker joined, a Broker died, a topic was removed or a topic was added, etc. Zookeeper provides an in-sync view of Kafka Cluster configuration.
Consumer: Consumers read from Kafka topics at their cadence and can pick where they are (offset) in the topic log.
Topic and Partition (Sharding)
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
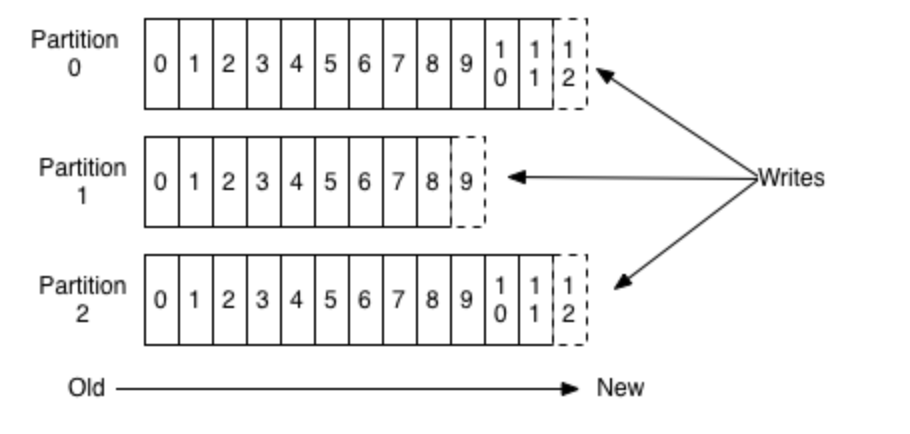
Each partition is an ordered, immutable sequence of records that is continually appended to a structured commit log. The Kafka cluster durably persists all published records using a configurable retention period.
The partitions serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Also each partition is replicated across a configurable number of servers for fault tolerance.
Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Consumer Group
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances. If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
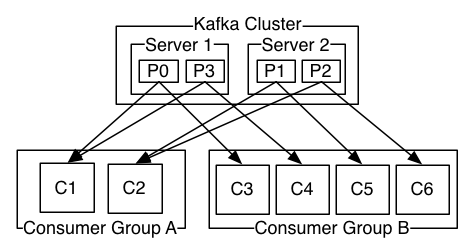
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
If you want to implement a message queue system, then you should just have a single consumer group for each topic to avoid your records being processed multiple times.
How consumers read from the partition?
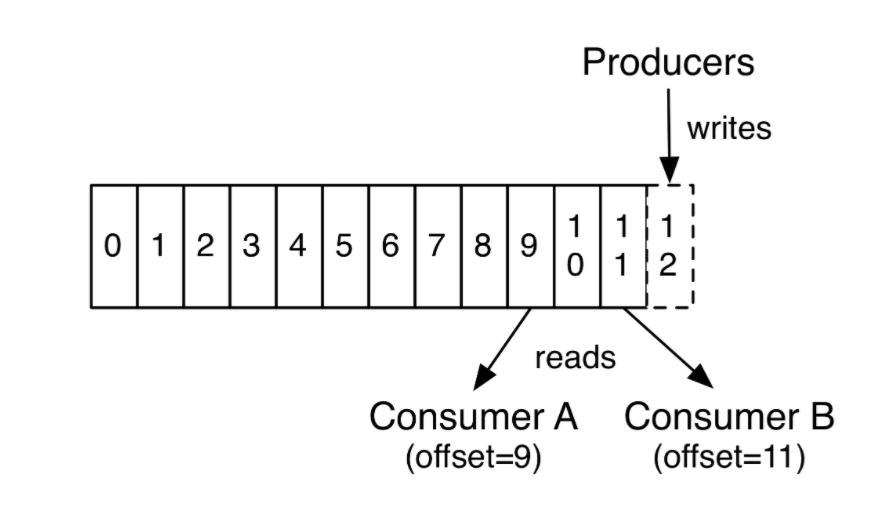
Kafka maintains a per-consumer basis offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
While implementing KafkaConsumer, it is important to understand that the KafkaConsumer is not thread safe. There are two options mentioned on how to handle this in the documentation here. Two approaches discussed are “one consumer thread per partition and topic” and “decoupling consumption and processing”.
Also the consumer can commit and communicate to the broker about the records that has been processed. The committed position is the last offset that has been stored securely. Should the process fail and restart, this is the offset that the consumer will recover to. The consumer can either automatically commit offsets periodically; or it can choose to control this committed position manually by calling one of the commit APIs (e.g. commitSync and commitAsync).
This is a good diagram to recap of what we just read.
Example
In the example we will have a launch a Kafka cluster i.e. start the zookeeper and the broker. Then we will produce events and see them being consumed.
Here is the link to the code uploaded in Github.
Here is a very good link which clearly articulates how to start the Kafka cluster.
Once the Kafka cluster is up and running we will create a Producer using the Producer API.
Then we will write a consumer to process the records that has been emitted using the Consumer API.
Create a Producer:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, Constants.KAFKA_BROKERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return new KafkaProducer<>(props);
Producer emitting records:
Producer<Long, String> producer = ConsumerProducerFactory.createProducer();
for (int index = 0; index < Constants.NUMBER_OF_PRODUCED_RECORDS; index++) {
final ProducerRecord<Long, String> record = new ProducerRecord<>(Constants.TOPIC_NAME, "This is record " + index);
try {
RecordMetadata metadata = producer.send(record).get();
System.out.println("Record sent with key " + index + " to partition " + metadata.partition() + " with offset "
+ metadata.offset());
} catch (ExecutionException | InterruptedException e) {
System.out.println("Error in sending record");
e.printStackTrace();
}
}
Create a Consumer:
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Constants.KAFKA_BROKERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, Constants.GROUP_ID_CONFIG);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
final Consumer<Long, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(Constants.TOPIC_NAME));
return consumer;
Process Records:
try (Consumer<Long, String> consumer = ConsumerProducerFactory.createConsumer()) {
int numOfRecordsToProcess = 50;
while (numOfRecordsToProcess > 0) {
ConsumerRecords<Long, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<Long, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<Long, String> record : partitionRecords) {
numOfRecordsToProcess--;
System.out.println(
"Record partition " + record.partition() + " -> " + record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
}
References
- https://kafka.apache.org/
- https://insidebigdata.com/2018/04/12/developing-deeper-understanding-apache-kafka-architecture/
- https://www.upsolver.com/blog/kafka-versus-rabbitmq-architecture-performance-use-case
- http://cloudurable.com/blog/kafka-architecture/index.html
- https://medium.com/better-programming/rabbitmq-vs-kafka-1ef22a041793

{kind=link}